Novel View Synthesis from Single Images via Point Cloud Transformation
Hoang-An Le, Thomas Mensink, Partha Das, Theo Gevers
Computer Vision Group, Informatics Institute, University of Amsterdam
Reading time ~3 minutes
Abstract
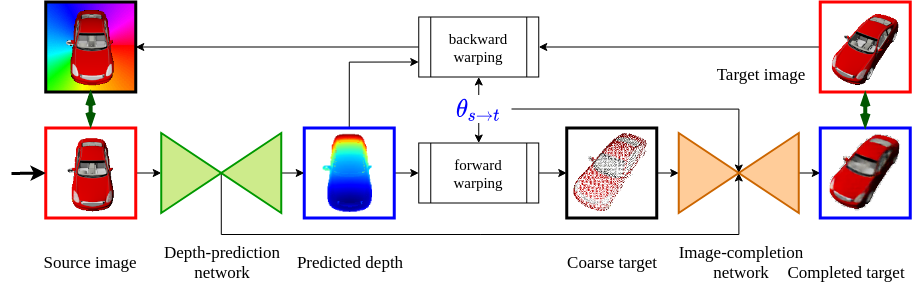
In this paper the argument is made that for true novel view synthesis of objects, where the object can be synthesized from any viewpoint, an explicit 3D shape representation is desired. Our method estimates point clouds to capture the geometry of the object, which can be freely rotated into the desired view and then projected into a new image. This image, however, is sparse by nature and hence this coarse view is used as the input of an image completion network to obtain the dense target view. The point cloud is obtained using the predicted pixel-wise depth map, estimated from a single RGB input image, combined with the camera intrinsics. By using forward warping and backward warping between the input view and the target view, the network can be trained end-to-end without supervision on depth. The benefit of using point clouds as an explicit 3D shape for novel view synthesis is experimentally validated on the 3D ShapeNet benchmark.

Paper
Presentation
Code
Coming soon at github
Citation
If you find the material useful please consider citing our work
@inproceedings{le20bmvc,
author = {Le, Hoang{-}An and Mensink, Thomas and Das, Partha and Gevers, Theo},
title = {{Novel View Synthesis from Single Images via Point Cloud Transformation}},
booktitle = {Proceedings of the British Machine Vision Conference (BMVC)},
year = {2020},
}